Introduction to R and Rstudio
Last updated on 2023-01-24 | Edit this page
Overview
Questions
- How do I use the RStudio IDE?
- What are the basics of R?
- What are the best practices for writing R code?
Objectives
- Understand how to interact with the RStudio IDE
- Demonstrate some R basics: operators, comments, functions, assignment, vectors and types
- Be aware of some good habits for writing R code
Why R?
The R language is one of the most commonly used languages in bioinformatics, and data science more generally. It’s a great choice for you because:
- Reproducibility: Scripting your analysis makes it easier for someone else to repeat and for you to re-use and extend
- Power:
Rcan be used to work with datasets larger than you can in Prism or Excel - Open source: So it’s free!
- Community:
Ris a popular choice for data science, so there are many resources available for learning and debugging - Packages: Since the community is large, many people have written helpful packages that can help you do tasks more easily than if you’d had to start from scratch
The other language most commonly used for data science is python. Some people might even consider it a better choice than R, because it doesn’t have some of the strange quirks that R does, and also has a large community of users (and all of the benefits that come with it).
I use both R and python, and most (but not all) people who do a lot of data science know how to use both. But today we’re learning R because I think it usually what I turn to when someone in the lab asks me for help analysing their data, and I think everyone can learn to use it for those same tasks too.
I made all of the material for this course (including the website and slides) in Rstudio using R. A little bit can take you a long way!
There’s more than one way to skin a cat
This course will teach a particular ‘dialect’ of R called the tidyverse. This is a collection of packages mostly written by Hadley Wickham, that focus on the concept of ‘tidy’ data.
You’ll soon discover that when coding, there are many ways of getting to the same output. Some of them are more efficient than others, and some of them are just easier to code than others. The tidyverse packages are hugely popular in the R community, and when I started I found them easy to work with.
However, if you stick with R long enough, you’ll probably end up needing to learn some additional base R (particularly if you use packages from outside the tidyverse). If you want to get a head start, I’ll include some links to resources at the end of this lesson.
Do I need to do this lesson?
Since we have a variety of skill levels and experiences in this course, every lesson will have a challenge at the start to check if the lesson contains anything new for you. If you can solve it, then you can skip the lesson.
Predict what will happen after every section of the following script (without running it in R).
Also be able to answer the question: what is a comment?
R
# section 1
100 ** 1
# section 2
a <- 4
b <- 3
a + b
# section 3
round(3.1415, digits=2)
# section 4
library(stats)
# section 5
stringr::str_length("what is the output?")
# section 6
as.integer(c(1.96,2.09,3.12))
# section 7
as.numeric(c("one", "two", "three"))
A comment is piece of text where each line starts with a hash (#). These are used to annotate code.
R
# section 1
100 ** 1
OUTPUT
[1] 100100 to the power of 1 is 100
R
# section 2
# assign the value 4 to variable a
a <- 4
# assign the value 3 to variable b
b <- 3
# add the values of a and b
a + b
OUTPUT
[1] 74 + 3 is 7
R
# section 3
round(pi, digits=2)
OUTPUT
[1] 3.14Using the round() function to round \(\pi\) to two decimal places gives the result 3.14
R
# section 4
library(stats)
No output, just loading the stats library.
R
# section 5
stringr::str_length("what is the output?")
OUTPUT
[1] 19You might need the help function for this one - there are 19 characters in the string.
R
# section 6
as.integer(c(1.96,2.09,3.12))
OUTPUT
[1] 1 2 3Coercing a vector of type double to integers truncates numbers to give integers.
R
# section 7
as.numeric(c("one", "two", "three"))
WARNING
Warning: NAs introduced by coercionOUTPUT
[1] NA NA NAThis one is tricky! Trying to coerce a string that isn’t only digits just results in NA values.
Introduction to RStudio
RStudio is an integrated development environment that makes it much easier to work with the R language. It’s free, cross-platform and provides many benefits such as project management and version control integration.
When you open it, you’ll see something like this:
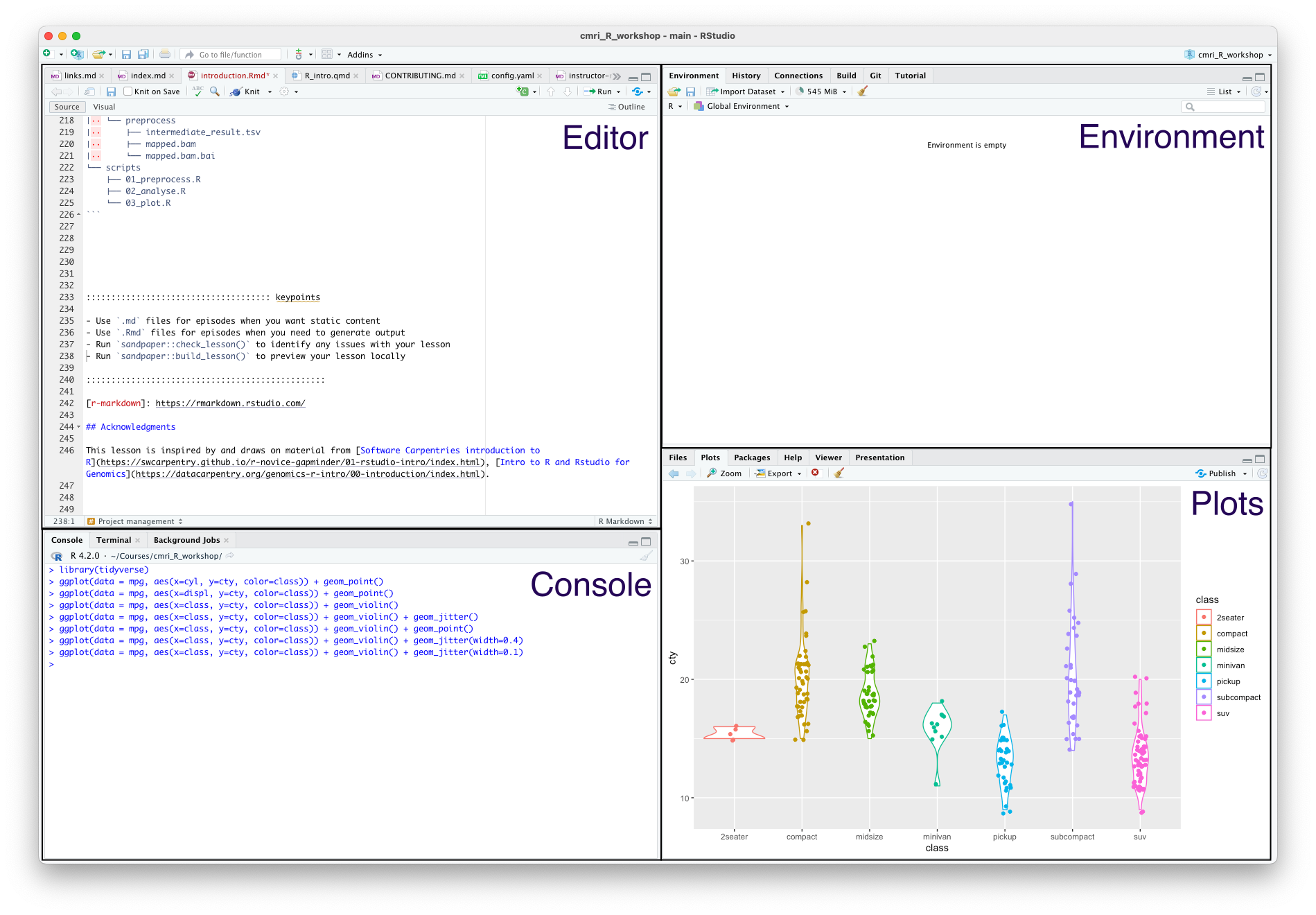
The four main panes are:
- Top left: editor. For editing scripts and other source code
- Bottom left: console. For running code
- Top right: environment. Information about objects you create will appear here
- Bottom right: plots (among other things). Some output (like plots) from the console appears here. Also helpful for browsing files and getting help
Organizing your work into projects
When you work in Rstudio, the program assumes that you’re working in a project. This is a directory that should contain all the files that you’ll need for whatever project you’re currently working.
If you’ve made a fresh install then by default you won’t be in a project. Otherwise, the current project will be the last one you opened.
Let’s make a new project for working in for this course. In the menu bar, click File > New Project, and decide if you’d like to start the new project in a New Directory or an Existing Directory, and then tell Rstudio where you want your project directory to be located.
Using the editor
The editor pane won’t appear in a new project, so open it up by making a new script. In the menu bar, click File > New File > R Script.
Although you can also type commands directly into the console pane (below), keeping your commands together in a script helps organise your analysis.
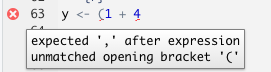
The editor also helps you identify issues with your code by placing a cross where it doesn’t understand something.

Hover over the cross to get more information
Using the console
The console is where you can type in R commands and see their output.
You can type R commands directly in here after the prompt (>). This prompt disappears while the code is running, and re-appears when it is done. To see this, try typing the following line of code into your console:
R
Sys.sleep(5)
The prompt disapers for five seconds, then comes back.
Rather than typing directly into the console, you can ‘send’ a line of code from the editor to the console by pressing Ctrl + Enter.
You can also run the whole script with Ctrl + Shift + Enter.
As a calculator
The most basic way we can use R is as a calculator:
R
1 + 1
OUTPUT
[1] 2If you type an incomplete command, you’ll see a +:
R
1 +OUTPUT
+Finish typing the command to get back to the prompt (>).
The order of operations is as you would expect:
- Parentheses
(,) - Exponents
^or** - Multiply
* - Divide
/ - Add
+ - Subtract
- - Modulus
%%
R
3 / (3 + 6)
OUTPUT
[1] 0.3333333You can also use R for logical expressions, like:
R
3 > 5
OUTPUT
[1] FALSEThe logical operators you’ll most likely use are
- Equal
== - Less than
< - Less than or equal to
<= - Greater than
> - Greater than or equal to
>=
You can also combine multiple logical statements, for example,
R
(3 > 5) | (4 < 5)
OUTPUT
[1] TRUEFor this, we use the operators:
- Logical or
| - Logical and
&
Writing R code
Next, we’ll look at some of the building blocks of R code. You can use these to write scripts, or type them directly into the console.
When performing data analysis, it’s best to record the steps you took by writing a script, which can be re-run if you need to reproduce or update your work.
Comments
The first building block is actually lines that are ignored by R: comments. Anything that comes after a # character won’t be executed. Use this to annotate your code.
R
# this is a comment
1 + 2 # this is also a comment
OUTPUT
[1] 3R
# the line below won't be executed
1 + 1
OUTPUT
[1] 2Comments is very important!!! A key part of reproducibility is knowing what code does. Make it easier for others and your future self by adding lots of comments to your code.
Assignment
If you want R to remember something, you can assign it to a variable:
R
my_var <- 1+1
print(my_var)
OUTPUT
[1] 2R
a <- 3
b <- 2
c <- (a * b) / b + 1
print(c)
OUTPUT
[1] 4Functions
A function is just something that takes zero or more inputs, does something with it, and gives you back zero or more outputs.

R comes with many useful functions that you can use in your code. A function is always called with parentheses ().
For example, the getwd() function takes no inputs, and returns the current working directory.
R
# a function that takes no inputs
getwd()
Base R also has many mathematical and statistical functions:
R
# natural logarithm
log(1)
OUTPUT
[1] 0R
# rounding
round(0.555555, digits=3)
OUTPUT
[1] 0.556R
# statistical analysis
sample1 <- c(1, 2.5, 3, 1, 1.3, 4.6)
sample2 <- c(1000, 1001, 3000, 5000, 2022, 4000)
t.test(sample1, sample2)
OUTPUT
Welch Two Sample t-test
data: sample1 and sample2
t = -4.0073, df = 5, p-value = 0.01025
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4379.9127 -956.6206
sample estimates:
mean of x mean of y
2.233333 2670.500000 You don’t need to memorize all these functions: Google is your friend.
RStudio can also help you with function usage. If you know what the name of a function is but can’t remember how to use it, you can type ? before the function name in the console to get help on that function.
R
?sin
If you don’t know what the name of a function is, you can type ?? before a key word to search the documentation for that key word.
R
??trig
Named arguments
Function arguments can be named implicitly or explicitly. When calling a function, explicitly named arguments are matched first, then any other arguments are matched in order.
For example, the documentation for the round function gives its signature: round(x, digits = 0).
The following function calls are all equivalent:
R
round(1/3, 3)
round(1/3, digits=3)
round(x=1/3, digits=3)
round(digits=3, x=1/3)
However, the last is not best practice: reversing the order of the arguments will likely be confusing for someone else reading your code.
In general, try to match the documentation when you call a function.
Which of the calls above matches the documentation for round()?
You can also write your own functions:
R
# function to add two numbers
my_add <- function(num1, num2) {
return(num1 + num2)
}
my_add(1,1)
OUTPUT
[1] 2R
?rnorm
R
rnorm(5, mean=1, sd=2)
OUTPUT
[1] -1.2508197 0.8529519 1.4416727 1.2751230 0.2460887Nested function calls
You can also nest function calls inside each other, for example:
R
mean(c(1,2,3))
OUTPUT
[1] 2This is equivalent to:
R
nums <- c(1,2,3)
mean(nums)
OUTPUT
[1] 2R
t.test( c(1, 2.5, 3, 1, 1.3, 4.6),
c(1000, 1001, 3000, 5000, 2022, 4000)
)
OUTPUT
Welch Two Sample t-test
data: c(1, 2.5, 3, 1, 1.3, 4.6) and c(1000, 1001, 3000, 5000, 2022, 4000)
t = -4.0073, df = 5, p-value = 0.01025
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4379.9127 -956.6206
sample estimates:
mean of x mean of y
2.233333 2670.500000 Notice that we can spread one ‘line’ of code over multiple lines of text. This can help with readability, by visually separating the two samples we’re comparing.
Using libraries
One of the great things about R is that a lot of other people use it, so often somebody has worked out an efficient way of doing things that you can use. This way, you don’t have to build your code from the ground up; instead you can use functions that other people have written.
When you use other peoples’ functions, they will be packaged in to libraries (also called packages) that you can import. In order to use library, it first must be installed. R provides the function install.packages() which you can use to install libraries from CRAN (an online repository of libraries).
R
install.packages("library_name")
Note the use of quotation marks around the library name - this tells R that this is a string, rather than a variable (more on strings in the next section).
R
install.packages("tidyverse")
Package-ception
Most of the packages that you’ll use will come from CRAN, but you might come across other sources of packages that are also useful. These are usually installed by packages that you can get from CRAN.
For example, the Bioconductor suite consists of packages that are useful for bioinformatics. To install any Bioconductor libraries, you’ll first need to install the BiocManager package from CRAN, and then use functions from this library to install Bioconductor packages.
R
# install BiocManager package
install.packages("BiocManager")
# use the install function from BiocManager to install the GenomicFeatures and karyoploteR libraries
BiocManager::install(c("GenomicFeatures", "karyoploteR"))
Another place you might install packages from is github. Many developers host their code for their package on github, and then release it to CRAN when they think it’s ready.
If you want to use the development version of a package (for example if you want to use a feature that hasn’t been released yet), you can get it directly from github using the devtools package. Be careful when you do this - you’ll get all the shiny newest features, but you might also run into new bugs that haven’t been fixed yet!
For example, if you want to install the development version of readr from github:
R
# install the devtools package
install.packages("devtools")
# use the install function from devtools to install readr
devtools::install_github("tidyverse/readr")
By default, the only functions that when you start up R are the base R functions. If you want to use any functions from libraries that you’ve installed, you’ll need to tell R which library they come from.
One way to do this is is to use the :: syntax: packagename::functionname(). For example, we can use the str_length() function from the stringr package as follows
R
stringr::str_length("testing")
OUTPUT
[1] 7R
str_length("testing")
ERROR
Error in str_length("testing"): could not find function "str_length"We get an error because R doesn’t know what the str_length() function is by default.
The other way to use functions from a library is to import all the functions in the library using the library() function. It’s best practice to put all the library() calls together at the top of your code, rather than sprinkling them throughout.
R
# import whole library
library(stringr)
# use the str_length function without ::
str_length("testing")
OUTPUT
[1] 7You can still use the packagename::functionname() syntax even if you’ve loaded the library. This makes it clear which library the function comes from, and some style guides recommend that you do this for every function you use.
Function conflicts
The order you load your packages is important. If two functions from two different packages you’ve loaded have the same name, the one you loaded last will be used. Sometimes packages will warn you about this - for example, when you load the tidyverse package (which is actually a collection of packages), you’ll see something like this.
R
library(tidyverse)
OUTPUT
── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.0 ✔ purrr 1.0.1
✔ tibble 3.1.8 ✔ dplyr 1.0.10
✔ tidyr 1.2.1 ✔ forcats 0.5.2
✔ readr 2.1.3
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()This tells us that the filter() function from dplyr has overwritten (or ‘masked’) the filter() function from the stats package, and there is a similar conflict for lag().
You can still use stats::filter() in your code, but you must explicitly specify that you want to use thestats package by prefixing it with stats::. If you just use filter(), you’ll get the version from dplyr.
Not all packages warn you about conflicts, so be careful you’re using the function that you think you’re using! This can be a source of strange errors, so try adding packagename:: in front of your function calls if you this this might be happening.
There’s no wrong or right answers here, but you might come across people that have (strong) opinions in this area.
Usually, if I’m only using one or two functions from a library, I won’t import the whole library, but just use the packagename::functionname() syntax. If I’m going to be using a lot of functions from a library, I’ll use library().
Some people consider it best practice to always use packagename::functionname(), since then it’s clear which packages are being used and where. This also helps avoid conflicts between functions with the same name in different packages.
However, this style is quite verbose (and a little distracting), and some people might say that this makes code written this way less readable. In practice, I haven’t come across much code that always uses explicit package names.
Vectors
One of the most common data structures R is the vector. These are collections of elements (technically called ‘atomic vectors’) like numbers, which are arranged in a particular order.
Vectors are often created with the concatenation function c():
R
# create a vector of three numbers
a_vector <- c(1,2,3)
# order matters!
a_different_vector <- c(2,1,3)
In R, vectors contain data of only one type. Some of the types you might see are:
- Double: real numbers which can take on any value (like 1.13, 6, -1004.29)
- Integer: whole real numbers (like 1, 2, -1)
- Character: strings of characters, enclosed in either single or double quotes
- Logical: booleans, either
TRUEorFALSE
R
# we can use the seq function to create vectors with numbers in them
double_vec <- seq(1, 10)
# add 'L' to the end of a number to tell R that it's an integer
integer_vec <- seq(1L, 10L)
# strings can be enclosed in single or double quotes
character_vec <- c("this", 'is', "a", 'vector')
# logicals are either TRUE or FALSE
logical_vec <- c(TRUE, FALSE)
You can get at the individual elements of a vector using brackets ([):
R
# first element of double_vec
double_vec[1]
# third to fifth elements of integer_vec
integer_vec[3:5]
#first and fourth elements of character_vec
character_vec[c(1,4)]
Declaring types
In some programming languages, like C and java, the programmer must declare the type of a variable when it’s created. In these statically typed languages, a variable declared as an integer can’t store any other types of data. As a dynamically typed language, R takes a looser approach to variable types.
If you try to create a vector that contains more than one type of element, all the elements will be transformed into the ‘lowest common denominator’ type. For example, concatenating an integer and double will result in a double vector.
R
# concatenating a double and an integer
numeric_vec <- c(5.8, 10L)
# the typeof function tells you the type of a variable
typeof(numeric_vec)
OUTPUT
[1] "double"One way to think about this is that elements are always coerced into the type that results in the least amount of information loss. The integers are a subset of all real numbers, so we can easily represent an integer 10L as the numeric 10. But if we tried to convert the real number 5.8 to an integer, how do we deal with the .8 part?
R
unknown_type <- c(1L, 1, "one")
print(unknown_type)
OUTPUT
[1] "1" "1" "one"R
typeof(unknown_type)
OUTPUT
[1] "character"It’s a character vector.
Character vectors can be used to represent numbers, but numbers can’t easily be used to represent characters.
R also has a way of representing missing data: there’s a special value in every type called NA (not available).
R
vec <- c(1, 3, NA)
Having NA values can change the way that functions interact with your data. For example, how would you take the mean of three values: 1, 2, and NA?
R
nums <- c(1, 2, NA)
mean(nums)
OUTPUT
[1] NAR doesn’t know how to do this, so it just returns NA.
R
mean(nums, na.rm=TRUE)
OUTPUT
[1] 1.5Use the additional named argument na.rm=TRUE
Best practices
Now you know the basics of R, there are a few best practices that you should follow on your journey. These aren’t hard and fast rules, but principles that you should aim to follow to make your code better and more reproducible.
Formatting and readability matters
You should always be able to come back to your code after a long break (months, years) and easily understand what it does.
One thing that helps with this is to follow a style guide like this one for the tidyverse
This covers things like:
- Commenting: do this a lot! It’s better to have more comments than fewer
- Each script should start with a description of what it does or what it’s for
- When you have to name something, use a name that makes sense. You’re more likely to understand what is contained in variable
my_peptidethan you are if it was calledporxorowobljldfibllkmb - Syntax and spacing: use spaces and newlines to make your code more readable, not less
- Line length: try to make horizontal scrolling unnecessary, which usually means lines are less than 80 characters
Don’t copy/paste code
In general, try to avoid copy-pasting blocks of code.
If you find you need to make a change to that code, you’ll need to edit all the copies. If you do this, it’s easy to miss somewhere that you copied it, or make a mistake when you change it.
If you find yourself needing to do the same task many times, it’s usually better to write a function instead.
Fail fast
This is a concept from the world of start-ups, in which it refers to the practice of trying things out at an early stage.
If it works already, great, but if it doesn’t, then you can move on more quickly to something that might work better.

Test your expectations
Try to frequently test your code to see that it does what you expect it to do. Getting into this habit helps guard against bugs.
There are lots of different ways to do this, from just trying out the code with a few different inputs to automated unit testing
Don’t forget also to test that your code doesn’t do things that you don’t expect it to do as well!
R
# define a function
plus_three <- function(num) {
return( num + 3 )
}
# should return 11
plus_three(8)
# should return 2
plus_three(-1)
# should raise an error
plus_three("ten")
You can use the function stopifnot to help you check things automatically.
Project management
Aim to keep your data, scripts and output organized. RStudio helps you with this with Projects, which can be used to store all of the files related to a particular piece of analysis. People write whole papers about this, but here are a few suggestions:
- Treat raw data and metadata as read-only. Put it in a folder called
dataand don’t write anything to that folder except for more raw data - Put source code in a folder called
src - Put files generated during analysis in a folder called
outorresults. It shouldn’t matter if this folder gets deleted, since you should be able to re-create its contents using your data and scripts - A
READMEfile can be useful for a broad overview of the project, and for explaining how to run the analysis - Keep track of the packages required for your analysis using
renv(forRprojects only), orconda(more general but has a few gotchas forRpackages)
That is, an organized project might look something like this:
my_great_project
├── README.md
├── data
│ ├── dataset_1
│ │ ├── dataset_1.R1.fq.gz
│ │ └── dataset_1.R2.fq.gz
│ ├── dataset_2
│ │ ├── dataset_2_1.R1.fq.gz
│ │ ├── dataset_2_1.R2.fq.gz
│ │ ├── dataset_2_2.R1.fq.gz
│ │ └── dataset_2_2.R2.fq.gz
│ └── metadata
│ ├── metadata_1.tsv
│ └── metadata_2.tsv
├── renv
│ └── activate.R
├── results
│ ├── analyse
│ │ └── fold_change.tsv
│ ├── plot
│ │ ├── phylogeny.pdf
│ │ └── taxa.pdf
│ └── preprocess
│ ├── intermediate_result.tsv
│ ├── mapped.bam
│ └── mapped.bam.bai
└── scripts
├── 01_preprocess.R
├── 02_analyse.R
└── 03_plot.RLinks and acknowledgements
As you begin your journey with R, you might find it helpful to refer to one-page summaries (or ‘cheat sheets’) that other people have compiled. For example, there are cheat sheets for:
Here are some other useful links
- R for data science
- fasteR, a course teaching (mainly) base R
- Ten Simple Rules for Reproducible Computational Research
- More information about installing R packages
This lesson is inspired by and draws on some material from Software Carpentries introduction to R, Intro to R and Rstudio for Genomics.
Keypoints
- Use RStudio for writing and executing
Rcode - Add comments to your code by starting a line with
# - Assign values to variables using the assignment operator
<- - Functions covert inputs to outputs
- Vectors are a collection of values of the same type
- Following best practices will help the with the correctness and readability of your
Rcode